세그먼트 트리 (Segment Tree)는 동적인 구간 질의를 효율적으로 처리할 수 있는 자료구조입니다.
예를 들어, 어떤 배열의 구간 \([l, r]\)의 원소 중 최소값을 알아내거나 구간 전체를 한꺼번에 갱신하는 등의 연산을 빠르게 할 수 있게 됩니다.
https://www.acmicpc.net/problem/2042
2042번: 구간 합 구하기
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000,000)과 M(1 ≤ M ≤ 10,000), K(1 ≤ K ≤ 10,000) 가 주어진다. M은 수의 변경이 일어나는 횟수이고, K는 구간의 합을 구하는 횟수이다. 그리고 둘째 줄부터 N+1번째 줄��
www.acmicpc.net
최대 \(10^6\)개의 원소로 이루어진 배열이 있습니다.
최대 \(20000\)개의 쿼리가 주어지는데, 각각의 쿼리마다 특정 인덱스의 값을 변경하거나 주어진 구간의 원소의 합을 구해야 합니다.
우선 배열의 원소가 변하지 않고 고정되어 있다면, 구간의 합을 구하는건 간단한 DP로 해결할 수 있음을 이전 글에서 설명한 바 있습니다.
https://anz1217.tistory.com/19
동적 계획법 (Dynamic Programming)
동적 계획법 (이하 DP)은 큰 문제를 분할하여 부분 문제들로 만든 다음, 각 부분 문제의 답으로부터 전체 문제의 답을 이끌어내는 방식의 알고리즘입니다. 그런데 이 정의 어디에서 본 적이 있는
anz1217.tistory.com
하지만 배열의 값이 변하게 된다면, 한번 갱신 될 때마다 최대 \(O(n)\)번의 DP배열 갱신을 해야 합니다.
이를 각 쿼리마다 처리하는 건 너무 느리기 때문에, 더 효율적인 방법을 생각해야 합니다.
분할정복의 아이디어를 이용해봅시다.
위와 같이 맨 처음원소부터 \(i\)번째 원소까지의 합을 저장하는 대신, 배열을 반으로 나눠 절반씩의 합을 저장해 놓는다면 어떨까요?
다음과 같은 배열이 있을 때,

이 배열의 부분 합을 절반씩 나눠서 저장해 놓는 것을 반복하면, 다음과 같이 됩니다.
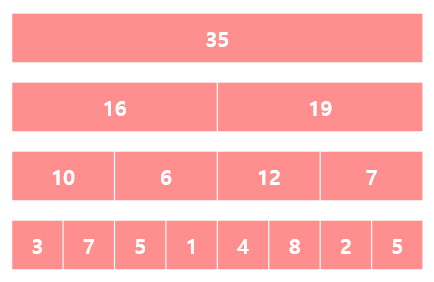
이 값들은 다음과 같은 이진 트리로 저장할 수 있게 됩니다.

일반적인 이진 트리는 배열로 쉽게 표현할 수 있다는 점까지 이용한다면, 배열을 이용해 세그먼트 트리를 쉽게 저장할 수 있게 됩니다.

(\(i\)번째 원소의 부모는 \(\lfloor \frac i2 \rfloor\)번째 원소, 자식은 \(2i\)번째와 \(2i+1\)번째 원소입니다.)
아무튼 이런 식으로 세그먼트 트리를 만들었다고 치고, 이를 이용해 실제 쿼리를 처리해봅시다.
먼저 구간 \([l, r]\)의 합을 구하는 쿼리입니다.
트리의 루트부터 탐색해봅시다.
현재 보고 있는 트리의 정점이 구간 \([s, e]\)를 나타내고 있다고 합시다.
구간 \([s, e]\)가 \([l, r]\)과 단 하나도 겹치는 점이 없다면, 무시하면 됩니다.
구간 \([s, e]\)가 \([l, r]\)에 완전히 포함된다면, 현재 정점에 포함되어있는 값을 더하면 됩니다.
그렇지 않다면, 현재 정점의 두 자식에 대해 재귀적으로 값을 계산한 뒤 더해주면 됩니다.

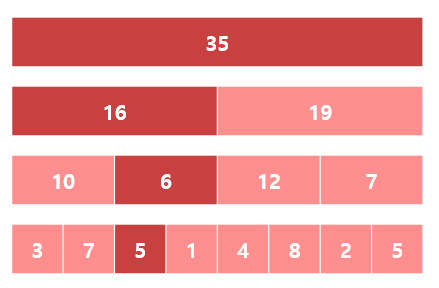
이 방법으로 위에서 만든 세그트리에서 구간 \([2, 6]\)의 합을 계산하면, 다음과 같이 3개의 원소의 합으로 구간의 합을 계산할 수 있게 됩니다.
시간복잡도는 어떻게 될까요?
어떤 임의의 구간에 대해 계산하더라도, 많아도 \(2\log n\)개의 원소의 값만 더하게 됨을 쉽게 알 수 있습니다.
따라서 구간 합을 구하는 쿼리의 시간복잡도는 \(O(\log n)\)입니다.
(\(n\) : 원소의 개수)
다음은 임의 원소 하나를 갱신하는 쿼리입니다.
역시 위의 세그먼트 트리에서 3번째 원소 하나를 갱신한다고 한다면, 많아도 \(\log n\)개의 원소만을 갱신하면 된다는 사실을 알 수 있습니다.
역시 시간복잡도는 \(O(\log n)\)입니다.
세그먼트 트리를 이용한 2042번 코드입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef pair<int, int> pii;
typedef pair<ll, ll> pll;
ll gcd(ll a, ll b) { for (; b; a %= b, swap(a, b)); return a; }
const int N = 1000001;
int n, m, k;
ll segTree[N * 4];
void update(int ptr, int s, int e, int i, ll val)
// 구간 [s,e]를 의미하는 segTree[ptr]을 보고 있고, i번째 인덱스를 val로 갱신하려고 한다.
{
if (s > i || e < i) return;
// 현재 보고 있는 구간이 i와 겹치지 않는다면 return한다.
if (s == e)
{
// s와 e가 같다면 (또 i와 같다면) 현재 원소를 val로 변경한다.
segTree[ptr] = val;
return;
}
// 그렇지 않다면
update(ptr * 2, s, (s + e) / 2, i, val); // 왼쪽 자식
update(ptr * 2 + 1, (s + e) / 2 + 1, e, i, val); // 오른쪽 자식
segTree[ptr] = segTree[ptr * 2] + segTree[ptr * 2 + 1];
// 각각 계산한다음 현재 정점의 값을 갱신해준다.
}
ll getVal(int ptr, int s, int e, int l, int r)
// 구간 [s,e]를 의미하는 segTree[ptr]을 보고 있고, 구간 [l,r]의 합을 계산하려고 한다.
{
if (s > r || e < l) return 0;
// [s,e]와 [l,r]이 겹치지 않는다면 의미 없는값 (0)을 return한다.
if (l <= s && e <= r)
{
// [s,e]가 [l,r]에 완전히 포함된다면 현재 정점에 저장된 값을 return한다.
return segTree[ptr];
}
// 그렇지 않다면
return getVal(ptr * 2, s, (s + e) / 2, l, r) // 왼쪽 자식
+ getVal(ptr * 2 + 1, (s + e) / 2 + 1, e, l, r); // 오른쪽 자식
// 각각 계산한 다음 더해서 return 해준다.
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n >> m >> k;
for (int i = 1; i <= n; i++)
{
ll a; cin >> a;
update(1, 1, n, i, a);
}
for (int i = 0; i < m + k; i++)
{
ll a, b, c; cin >> a >> b >> c;
if (a == 1) update(1, 1, n, b, c);
else cout << getVal(1, 1, n, b, c) << '\n';
}
}
|
세그먼트 트리를 이용하면 결합법칙이 성립하는 모든 연산에 대해 (합, 곱, 최대/최소값, xor, GCD...), 단일 갱신과 구간 연산을 \(O(\log n)\)에 할 수 있게 됩니다.
위와 같은 연산을 처리할 수 있는 비슷한 자료구조가 하나 더 있습니다.
바로 펜윅 트리(Fenwick Tree, Binary Indexed Tree, BIT) 입니다.
펜윅 트리는 단일 원소 갱신과 첫 원소부터 임의의 원소까지의 구간 (\([1, r]\))에 대해 구간 연산을 \(O(log n)\)에 처리하는 자료구조입니다.
펜윅 트리는 구간 합을 다음과 같이 세그먼트 트리에서 오른쪽 자식을 없앤 형태로 저장합니다.
(실제로는 약간 다릅니다.)

$$\{3,10,5,16,4,12,2,35\}$$
이런 방식으로 구간 합을 저장하면 각각의 \(i\)번 인덱스로 끝나는 부분 구간합은 무조건 1개씩만 존재하게 되므로, \(O(n)\)의 공간복잡도만으로도 트리를 저장할 수 있습니다.
예를 들어, 4번 인덱스로 끝나는 부분 합은 구간 \([1,4]\)이며, 4번 인덱스에는 이 구간의 합인 16이 저장됩니다.
6번 인덱스로 끝나는 부분 합은 구간 \([5,6]\)이며, 6번 인덱스에는 이 구간의 합인 12가 저장됩니다.
펜윅 트리를 이용해 구간 \([1, 7]\)의 합을 구하는 쿼리를 처리해 봅시다.
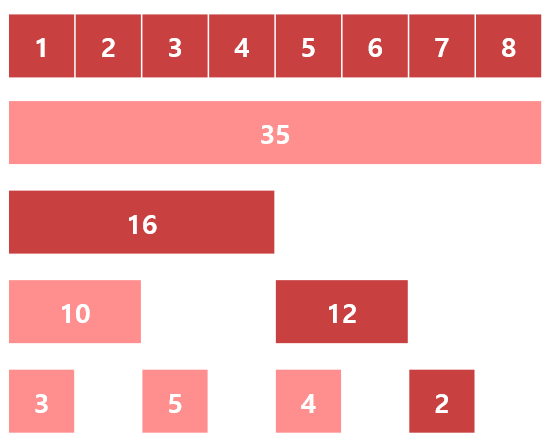
5까지의 합을 구하기 위해서는 다음과 같이 3개의 원소 \([1,4], [5,6], [7,7]\)의 합을 더하면 됨을 알 수 있습니다.
일반적으로 펜윅트리는 모든 원소가 나타내는 구간의 크기가 \(2^n\)꼴이므로, 이를 구현하는데 비트연산을 이용합니다.
합을 구할 때는, 값이 1인 비트 중 가장 하위 비트를 계속 빼 나감으로써 구할 수 있습니다.
\(7\)를 2진수로 나타내면 \(111_2\)입니다.
여기에서 값이 1인 가장 하위 비트 (\(1_2\))을 빼면 \(6\) (\(110_2\))이고,
또 값이 1인 가장 하위 비트 (\(10_2\))를 빼면 \(4\) (\(100_2\))가 됩니다.
여기에서 한 번 더 연산을 하면 \(0\)이 되므로 종료합니다.
지금까지 나온 값 (\(7,6,4\)) 인덱스에 저장된 값 (\(2,12,16\))을 더하면 \([1,7]\)의 구간합이 됨을 알 수 있습니다.
시간복잡도는 \(r\)의 비트 수에 비례하므로 \(O(\log n)\)입니다.
(\(n\) : 원소의 개수)
다음은 임의의 하나의 원소를 갱신하는 쿼리를 처리해 봅시다.
\(5\)번째 원소를 갱신한다고 할 때, 갱신해 줘야 하는 원소는 다음과 같습니다.
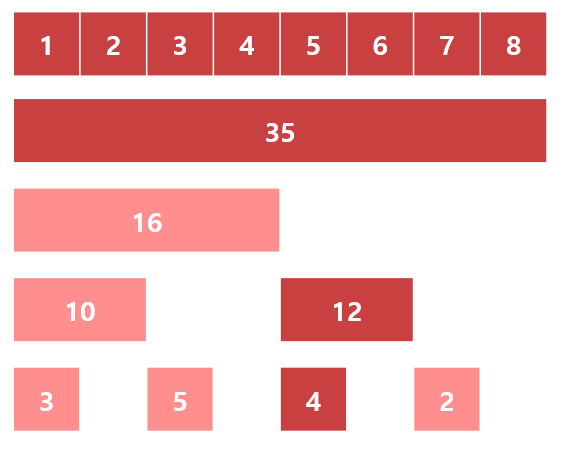
좀 전에 구간 연산에서는 값이 1인 비트 중 가장 하위 비트를 빼 나감으로써 필요한 원소들을 탐색 했습니다.
값을 갱신할 때는 반대로, 값인 1인 가장 하위 비트를 더해 나가면 필요한 원소들을 모두 구할 수 있습니다.
\(5\)를 2진수로 나타내면 \(101_2\)입니다.
여기에서 값이 1인 가장 하위 비트 \(1_2\)를 더하면 \(6\) (\(110_2\))이 됩니다.
또 값이 1인 가장 하위 비트 \(10_2\)를 더하면 \(8\) (\(1000_2\))이 됩니다.
여기에서 한 번 더 연산을 하면 전체 구간의 크기 \(8\)을 초과하므로 종료합니다.
지금까지 나온 값 (\(5,6,8\)) 인덱스에 있는 값을 각각 갱신하면 된다는 사실을 확인할 수 있습니다.
시간복잡도는 역시 \(O(\log n)\)입니다.
지금까지 "값이 1인 가장 하위 비트" 라는 개념을 많이 사용했는데, 이 값은 일반적으로 (x & -x)라는 식으로 쉽게 구할 수 있습니다.
또, 이와 같이 구간 \([1,r]\)의 합을 구하는 연산을 할 수 있다면, 임의의 구간 \([l,r]\)의 합은 다음과 같이 구할 수 있습니다.
(구간 \([1,r]\)의 합 - 구간 \([1, l-1]\)의 합)
그렇기 때문에 펜윅 트리는 세그먼트 트리와는 달리 역원이 존재하는 연산에 대해서만 사용할 수 있습니다.
다음은 펜윅 트리를 이용한 2042번 코드입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef pair<int, int> pii;
typedef pair<ll, ll> pll;
ll gcd(ll a, ll b) { for (; b; a %= b, swap(a, b)); return a; }
const int N = 1000001;
int n, m, k;
ll arr[N];
ll segTree[N];
void update(int i, int x)
{
while (i <= n)
{
segTree[i] += x;
i += i & -i;
}
}
ll getVal(int i)
{
ll res = 0;
while (i)
{
res += segTree[i];
i -= i & -i;
}
return res;
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n >> m >> k;
for (int i = 1; i <= n; i++)
{
ll a; cin >> a;
arr[i] = a;
update(i, a);
}
for (int i = 0; i < m + k; i++)
{
ll a, b, c; cin >> a >> b >> c;
if (a == 1) update(b, c - arr[b]), arr[b] = c;
else cout << getVal(c) - getVal(b - 1) << '\n';
}
}
|
세그먼트 트리와 펜윅 트리는 둘 다 값 갱신과 구간 연산의 시간복잡도가 \(O(\log n)\)입니다.
세그먼트 트리는 상수가 크기 때문에 펜윅 트리보다 더 느리게 작동하며, 구현이 복잡하고 메모리도 더 필요하지만,
역원이 없는 연산이라도 구간 연산이 가능하고, 추후 설명할 Lazy propagation이라는 방법으로 구간에 대한 갱신도 가능합니다.
펜윅 트리는 세그먼트 트리에 비해 좀 더 빠르게 작동하며, 구현도 간단하고 메모리도 적게 필요하지만,
범용성이 떨어져서 일부 연산에 대해서만 사용할 수 있다는 단점이 있습니다.
두 방식 모두 알아뒀다가 상황에 맞춰 더 적합한 자료구조를 사용하도록 합시다.
제 그룹의 문제집에서 연습 문제들을 관리하고 있습니다.
문제집의 문제들을 보고 싶으시다면, 가입 신청을 해 주세요.
ANZ1217
무슨 내용을 넣어야 좋을까요?
www.acmicpc.net
'알고리즘 > 자료구조' 카테고리의 다른 글
| 세그먼트 트리 응용 (0) | 2021.08.02 |
|---|---|
| 세그먼트 트리 with Lazy propagation (1) | 2020.06.01 |
| 유니온 파인드 (Union-Find) (0) | 2020.05.04 |
| 내장 라이브러리가 있는 자료 구조 (0) | 2020.04.28 |

